Linux iptables and eBPF: manipulating and monitoring network on the Linux kernel
Iptables is an essential userspace application used for the network filtering/firewall rules definition and enforcing them. Linux kernel implements netfilter framework which gives the user possibility to read and manipulate network packets via kernel modules that registers callback functions on a set of netfilter hooks.
The traveling of the packet through the Linux Kernel is shown below.

Since Linux kernel 4.8 XDP eBPF was introduced in the Kernel. It is a virtual machine running directly in the Kernel. XDP eBPF allows the third-party eBPF program to manage the packets. It means that Linux can use other software than the iptables to process the packets. This can help in achieving high-speed packet filtering where it is needed.
In the picture above it can be ignored since it is passing the packets to the netfilter. We will discuss eBPF in the networking later on.
The flow above depicts in detail how the packet is flowing when entering the Linux kernel. We will simplify the flow above to pinpoint the strategic points for the basic understanding of flow.
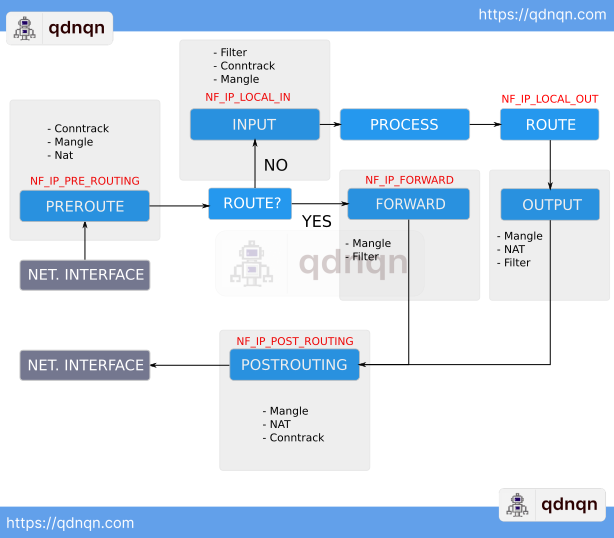
Netfilter hooks trigger at the specific points in protocol stack:
- PREROUTE (NF_IP_PRE_ROUTING Hook)
This hook triggers before routing happens - INPUT (NF_LOCAL_IN Hook)
This hook triggers before handing out a packet to the local process - FORWARD (NF_IP_FORWARD Hook)
This hook triggers before forwarding occurs - OUTPUT (NF_LOCAL_OUT Hook)
This hook triggers before giving back the packet from the local process - POSTROUTING (NF_IP_POSTROUTING Hook)
This hook triggers before going out on the exit interface
Using so is also maintaining different tables: Mangle, Nat, and Filter. Iptables are using these tables and hooks to enforce action on the specific packet matches.
We need to define the next terms used in the iptables:
- Tables
- Chains
- Targets
- Rules
Iptables Tables
There are 5 tables.
qdnqn@qdnqn:~$ sudo cat /proc/net/ip_tables_names
security
raw
mangle
nat
filter
Per table, definitions are given on the iptables man page.
Each table, serves its own purpose. If not specified when using iptables cli, the filter table is the default.
In this article, focus will be on the next three tables:
- mangle
- nat
- filter
Iptables Chains
Each table listed above contains chains. Chains are list of rules that can match set of packets. Every rule defined in the chain defines what to do with packet that matches the rule. The action to do on a packet is called target.
We will analyze three tables in this article:
- Filter table with default chains: INPUT, OUTPUT, and FORWARD.
- Nat table with default chains: PREROUTING, POSTROUTING, OUTPUT.
- Mangle table with default chains: INPUT, OUTPUT, FORWARD, PREROUTING, and POSTROUTING.
qdnqn@qdnqn-0:~$ sudo iptables -L | grep Chain
Chain INPUT (policy DROP)
Chain FORWARD (policy DROP)
Chain OUTPUT (policy ACCEPT)
Chains in the filter table
qdnqn@qdnqn-0:~$ sudo iptables -L -t nat | grep Chain
Chain PREROUTING (policy ACCEPT)
Chain INPUT (policy ACCEPT)
Chain OUTPUT (policy ACCEPT)
Chain POSTROUTING (policy ACCEPT)Chains in the nat table
qdnqn@qdnqn-0:~$ sudo iptables -L -t mangle | grep Chain
Chain PREROUTING (policy ACCEPT)
Chain INPUT (policy ACCEPT)
Chain FORWARD (policy ACCEPT)
Chain OUTPUT (policy ACCEPT)
Chain POSTROUTING (policy ACCEPT)
Chains in the mangle table
Iptables Rules
Rules are deciding the fate of the packet. Each rule defines the expression on which are packets matched and the action to be taken on the match. If the packet is matching rule then the defined action is taken. If the rule is not matching the packet then the cursor is passed to the next rule in the chain. If no rule matches the packet then the default action is taken - a.k.a. POLICY.
qdnqn@qdnqn-0:~$ sudo iptables -L
Chain INPUT (policy DROP)
target prot opt source destination
ufw-before-logging-input all -- anywhere anywhere
ufw-before-input all -- anywhere anywhere
ufw-after-input all -- anywhere anywhere
ufw-after-logging-input all -- anywhere anywhere
ufw-reject-input all -- anywhere anywhere
ufw-track-input all -- anywhere anywhere
Rules in the INPUT chain of the filter table
We can see that the targets above are all other chains maintained by the ufw. Ufw is a Ubuntu firewall manager that abstracts the iptables from the end-user and provides easy to use cli to apply firewall rules. In the background it relies on the iptables.
Iptables Target
Target can jump to user-defined chain, targets from the iptables-extensions, and one of the default targets.
Rules in the chain are walked one by one. If the rule in the chain matches to the packet - target is applied. If the rule doesn't match then the next rule is checked. The process is continued to the end of the chain. If no rules are matched the default behavior occurs which is called POLICY.
qdnqn@qdnqn-0:~$ sudo iptables -L | grep policy
Chain INPUT (policy DROP)
Chain FORWARD (policy DROP)
Chain OUTPUT (policy ACCEPT)
There are three default targets:
- ACCEPT: Let the packet in.
- RETURN: Stop walking in this chain and return to the previous one.
- DROP: Drop the packet without notifying the sender.
An additional useful target is REJECT which drops the packet and sends the error to the sender to know that firewall rejected the packet.
Linux network interfaces
Linux network interfaces can be:
- Physical network interface
- Virtual network interface
The physical network interface is a piece of network hardware (Network card) represented in the Linux Kernel.
Virtual network interface is a virtual interface that mimics the physical one and can act like it is a piece of hardware.
Eg.
qdnqn@qdnqn-0:~$ ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ef:f1:18:e8 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet REAL_PUBLIC_IP netmask 255.255.255.0 broadcast 84.22.105.255
ether 00:1a:4a:7c:4b:81 txqueuelen 1000 (Ethernet)
RX packets 3912694 bytes 1820963757 (1.8 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1826720 bytes 1684637657 (1.6 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 180 bytes 15966 (15.9 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 180 bytes 15966 (15.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
We can see that there are 3 interfaces:
- docker0 (Virtual)
- ens3 (Physical)
- lo (Virtual)
The network interface docker0 is the virtual one and managed by the docker to enable docker networking for the containers. Why virtual interfaces is useful? It is a great asset to have an isolated network on the hardware so that you can implement rules for the specific interface and implement gatekeeping to allow/disallow external network to connect to it.
Using Linux as the router
First IP forwarding must be enabled for the Linux to act as a router.
To check if IP forwarding is enabled run:
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0 # 0 means IP forward is disabled.The kernel variable net.ipv4.ip_forward is controlling IP forwarding capabilities.
$ sysctl -w net.ipv4.ip_forward=0
$ sysctl -p
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1 # 1 means IP forward is enabled.
sysctl is a software utility of some Unix-like operating systems that reads and modifies the attributes of the system kernel such as its version number, maximum limits, and security settings.[1] It is available both as a system call for compiled programs, and an administrator command for interactive use and scripting. Linux additionally exposes sysctl as a virtual file system.
– Wikipedia
If the packet is targeting a destination IP address that is not on the local network Linux acts as a router and inspects the routing table to forward the packet to the specified IP.
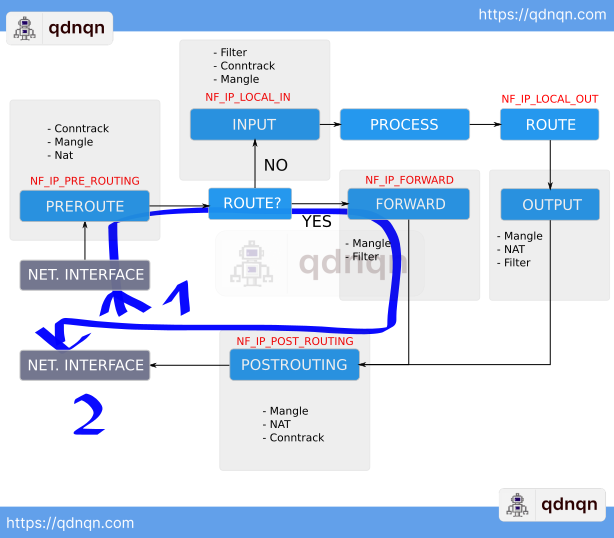
If the packet is targeting a destination IP address that is on the local network Linux forwards the packet to the local process which is listening on the specified socket.
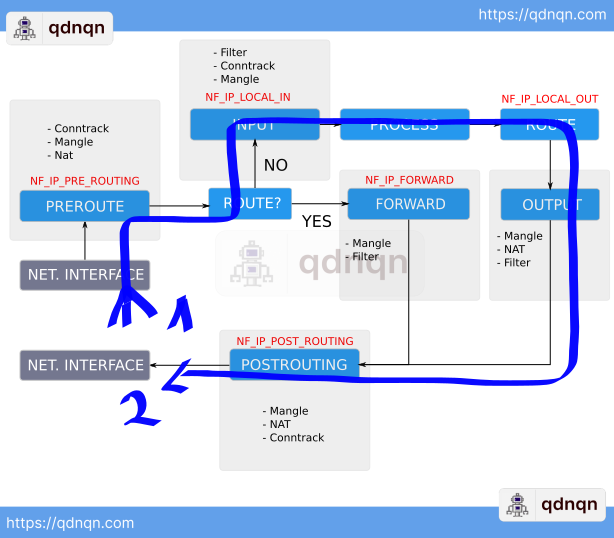
As you can see depending on the scenario different tables are inspected on the packet path through the Linux kernel.
Monitoring network traffic
Iptables also allow tracking packets and seeing the logs directly in the Kernel system logs. When adding a specific rule you can duplicate the same rule and add action LOG.
$ iptables -A INPUT -s 105.105.105.105 -j LOG
$ iptables -A INPUT -s 105.105.105.105 -j DROP
Now listing the logs will output everytime the packet is dropped for the specific rule.
$ sudo journalctl -feBPF
As mentioned before XDP eBPF gives the possibility for the third-party eBPF program to manage the packets. eBPF stands for the extended Berkeley Packet Filter. It acts as a virtual machine running in the Kernel which allows the end users to run the eBPF programs inside the Kernel. This gives the possibility to inspect and manipulate network packets using these third-party programs instead of for example using iptables.
eBPF initial possibilities were manipulating packets. Now it extends the possibilities even more and as stated on the official site of the eBPF is said next:
BPF originally stood for Berkeley Packet Filter, but now that eBPF (extended BPF) can do so much more than packet filtering, the acronym no longer makes sense. eBPF is now considered a standalone term that doesn’t stand for anything. In the Linux source code, the term BPF persists, and in tooling and in documentation, the terms BPF and eBPF are generally used interchangeably. The original BPF is sometimes referred to as cBPF (classic BPF) to distinguish it from eBPF.
– ebpf.io
The project landscape of projects using eBPF is listed on the project landscape on the official site.
A few categories where eBPF is making an entrance are listed below.
Network monitoring using eBPF
The pwru is one of the projects enabling network monitoring with powerful filtering of packets.
 cilium
cilium
Pwru enables tracking network packets in the Linux kernel with powerful filter functions.
Kubernetes networking using eBPF
eBPF is heavily utilized for network implementation on projects like Kubernetes. Achieving a high-speed network is done using eBPF networking implementation.
The two most popular network implementations for the Kubernetes are:
They rely on packet filtering and packed manipulation using eBPF programs instead of using iptables for example.